반응형


- 패딩이나 stride를 고려하지않고 (77) 이미지를 (33) 필터를 쓰면 (5*5)의 결과가 나온다.
- 7-4+1 = 5
- 적용하고자 하는 필터에 따라 같은 이미지가 Blur, Emboss, Outline등의 형태로 나올 수도 있다.
RGB Image Convolution
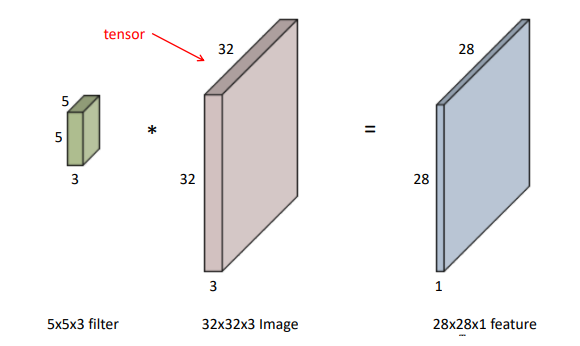
- 32-5+1 을 통해 28이 나오게 되며 (32323)의 이미지를 (55)의 필터를 사용한다하면 (553)이라는 필터를 사용한다는 것을 의미한다. 이는 2828*1의 피쳐를 갖게된다.
- 위의 필터가 필터가 4개가 있다면, 채널이 4인 (28284)의 피쳐를 갖게된다.
- 인풋 채널과 아웃풋의 채널을 알면 필터의 채널도 알 수 있다.
Stack of Convolutions

- (32323)의 인풋이 (28284) 값으로 나오게 될려면 필터가 (553)이 4개있어야함을 알 수 있다.
- 마찬가지로, (28284)라는 인풋이 (242410)의 아웃풋이 될려면 필터(554)가 10개 있어야한다. 이러한 필터의 숫자를 파라미터 숫자라고 한다.
- 파라미터의 숫자를 잘 정의해야한다.
CNN(Convolution Neural Networks)
- CNN은 convolution latyer, pooling layer 그리고 fully connected layer로 구성된다
- convolution and pooling layers는 feature extraction(이미지에서 중요한 정보를 추출)에 사용된다.
- Fully connected layer는 decision making에서 사용된다(분류문제)
- 최근에는 fully connected layer을 없애거나 최소화하는 추세이다.
- 학습해야하는 모델의 파라미터 숫자에 너무 의존적이기 때문.
- 파라미터 숫자가 너무 클수록 일반화 성능이 떨어짐
- 새로운 아키텍쳐를 볼때 몇개의 레이어, 파라미터를 가지고 있는 감을 가지는게 중요하다
Stride

- Stride가 1인 경우 7개의 인풋과 3개의 커널(채널)이 있다면 5개의 아웃풋이 나옴.
- Stride가 2인경우 7개의 인풋과 3개의 채널이 있다면 2칸을 옮겨 3개의 아웃풋이 나옴
Padding
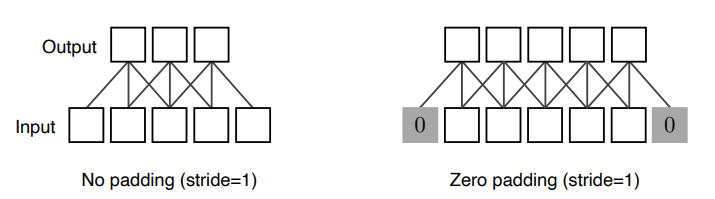
- (32*32)의 인풋이 같은 크기의 아웃풋이 나올 수 없는 이유는 바운더리 정보가 버려지기 때문이다.
- 패딩은 바운더리 정보를 채워주는 것을 의미한다.
- 패딩이 없다면 위에서 처럼 (55)의 이미지가 stride가 1일때 3개의 채널로 (5-3+1)에 의해 3개의 아웃풋이 나오지만, zero패딩을 해주면 (55)로 결과를 산출해낼 수 있다.
- 2번처럼 적절한 크기의 zero_padding과 stride=1 적용해주면 같은 크기의 아웃풋을 뽑아낼 수 있다.
Convolution Arithmetic

- 기본적으로 필터와 인풋의 채널(커널) 크기는 같아야함. 위에서(33)의 커널은 자동으로 (33*128)의 필터를 가진다. 궁극적으로 64개의 결과를 원하므로 파라미터의 숫자는
- 33128이 64개를 가져야하므로 33128*64개의 파라미터가 필요하다.
- 나중에 다른 모델들을 볼때 레이어의 모양만 봐도 파라미터를 구하는 방법에 대한 감이 생겨야함(10만,100만 단위가 필요함)
연습문제!

- 위의 모델(alexnet)에서 필요한 파라미터 수?!
- 일단 첫번쨰로 입력에서 들어온 레이어가 (2242243)임을 알수 있고 이를 (11*11)의 커널로 stride =4 를 적용하고 있음.
- 이는 각각 한개의 커널은 (11113)으로 이루어져있음을 알 수 있다. 위에서 인풋과 커널의 채널은 같다했음으로(커널,채널,필터 말이 각각 헷갈리는데 필터 = 커널로 보고 하나의 컨볼루션, 채널은 갯수로 생각하자 3처럼!)
- 위의 질문으로 돌아가보면 11113의 커널이 48의 채널 아웃풋을 위해서 똑같이 48개를 가져야하므로 11113*48이 된다.
- 원래는 96의 채널 아웃풋을 만들어야하는데 482를 한 이유는 컴퓨터의 메모리 용량이 부족해서 다른 네트워크를 이용해서 482를 적용함
- 두번째로, 커널을 (5548)로 사용하고 있으면서 아웃풋이 128의 채널이므로 필요한 파라미터 수는 (5548128) 또 역시 2개의 네트워크로 분산해서 곱하기 2까지 하면 (5548128*2)이다.
- 똑같이 이어가면서 연습해보자
- 가다보면 dense layer를 만나게 되는데 이는 fully connected layer이고 인풋에 있는 파라미터 개수와 아웃풋에 있는 파라미터의 개수를 곱한것이다.
- 이때 파라미터는 어마어마하게 커진다.
- dense layer가 말도 안되는 파라미터를 가지게 되는 이유는 각각의 하나의 커널이 모든 위치에 동일하게 적용되기 때문이다.
- 뉴런네트워크의 성능을 위해선 파라미터를 줄이는게 중요한데 이렇게 파라미터를 늘리면 안되기에 뒷단의 dense layer를 줄이고 앞단의 convolution layer를 늘리는게 트렌드임. 이러한 시도들이 one by one convolution이 탄생하게 됨.
- 깊이는 점점 깊어지고 파라미터 수는 줄이게 하는 방법들이 탄생
1x1 Convolution

- (1*1)이라는건 이미지에서 한 픽셀만 보고 채널 방향으로 줄이는 것
- 여기서 dimension은 채널을 의미함 (256*256)은 유지한채 채널만 128에서 32로 줄임
- 이렇게 깊이는 깊어지고 성능이 올라가도 파라미터 수를 줄일 수 있음.
- bottlenect architecture에서 자주 사용
본 내용은 네이버 커넥트 재단의 교육 컨텐츠를 참고하였습니다.
반응형
'Study > AI' 카테고리의 다른 글
| [AI] 다양한 최적화 방법 (0) | 2023.03.26 |
|---|---|
| [AI] Recurrent Neural Networks(RNN) (0) | 2023.03.26 |
| [Pytorch] 모듈과 데이터셋 + 데이터로더 (0) | 2023.03.19 |
| [Pytorch] 파이토치 기초 (1) | 2023.03.19 |
| [AI] 딥러닝 기초 (0) | 2023.03.12 |