반응형
유튜브 추천시스템의 2번째 논문인 Deep Neural Networks for YouTube Recommendations에 대한 요약을 진행 했습니다! Candidate generation과 rank 시스템을 이용하여 동영상을 추천해주고 개인별 동영상 시청시간까지 예측하는 과정에 대해서 배울 수 있었습니다.
논문 : https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf

1. 소개
- Scale : 너무 방대한 규모의 유튜브 유저와 제한된 컴퓨팅 파워
- Fresheness : 기존의 많은 비디오와 새로운 비디오 와의 적절한 탐색과 활용이 중요함
- Noise : sparisty와 다양한 외부 요인들로 인해 예측이 어려움
텐서플로우가 대규모 분산 학습을 사용하여 다양한 심층 신경망을 실험해볼 수 있는 유용한 프레임 워크를 제공하면서 이를 추천시스템에 접목시켜봄
딥러닝을 활용한 추천시스템 성능 향상에 집중(10억 개의 파라미터 학습, 수 천 억개의 데이터를 학습)
2. 전반적인 구조

- 전반적인 구조는 위와 같음
- 비디오 corpus 비디오 시청 ID와 검색 기록 + 인구통계학적인 정보를 바탕으로 유사도가 높은 candidate generation 후보군 추출
- 해당 후보군과 이전 작업을 바탕으로 생성된 cadidates들을 추가
- 비디오와 유저들을 설명하는 피쳐를 바탕으로 score를 부여하여 우선순위를 매긴 추천 영상 리스트 생성
- 추가로 A/B테스트 진행 → 유저의 참여를 확인하기 위해 CTR과 감상시간을 비교
3. Candidate Generation
- 비디오 추천을 extreme multiclass classification로 정의
- 수백 만개의 비디오 중에서 softmax 함수를 사용하여 하나의 비디오를 추천하는 분류 문제로 정의함.
- user(U), context(C)가 주어지면 특정 시간(t)에 해당 비디오(i)를 볼 확률을 구함

- (v: context embedding, u: user embedding)
- 좋아요처럼 explicit feedback을 사용할 수 있지만 유저가 비디오를 봤다는 것을 postive example로 학습시키기 위해 implicit feedback 사용
3.1 Model

“Efficient Extreme Multiclass”
- 유저가 본 영상과 검색이력을 각각 임베딩
- 여러 영상의 임베딩을 평균하여 고정된 크기의 input으로 바꿈
- 성별이나 인구통계학적인 피쳐들 즉 ,georaphic embedding 생성하여 다같이 concatenate
“Example Age”
- history 데이터를 기반으로 학습하면 오래된 아이템이 더 많이 추천됨
- 데이터의 age(생성한지 얼마나 됐는지)를 담은 정보를 feature로 추가
- 머신러닝은 과거 데이터에 편향되는 특징이 있는데 example age를 통해 최신 콘텐츠인지 여부도 같이 학습 할 수 있음
- 이를 통해 최신의 데이터를 추천해 줄 수 있는 freshness의 효과를 지님
“training”
- 위의 모든 임베딩 데이터를 하나로 concatenate한 것이 user data이며 fully connected Relu를 거쳐 output으로 최종 유저 임베딩을 생성
- 이후 softmax를 통해 어떤 영상을 볼 것으로 예상되는지 영상별 가중치가 output으로 나옴
3.2 Serving
- 요청이 왔을 때 상위 N개의 영상 추천
- 유저벡터와 모든 비디오 벡터의 내적을 계산하고 Nearest Neigbor index를 뽑아서 가장 가까운 아이템을 찾음
4. Ranking
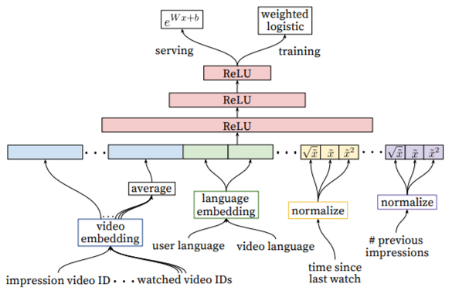
4.1 특징
- 노출(impression) 데이터를 사용하여 사용자 맞춤별로cadidate 예측을 보정하는 것이 Ranking의 목표
- 좀 더 많은 사용자와 관련된 feature 및 비디오와 관련된 정보를 사용함.
- 로지스틱 회귀를 사용하여 각 비디오마다 독립적인 점수를 매긴 후 순서대로 노출 시킴
- 노출당 예상 시청시간을 목표로 A/B 테스트 결과를 통해 지속적인 최종 순위를 조정
4.2 Feature Engineering
- 딥러닝을 통해 feature engineering의 비용을 완화했음에도 여전히 수 백개의 feature를 사용해 많은 비용이 발생
- 주요 과제는 유저 행동의 시간적인 시퀀스와 비디오 노출간의 관계를 찾는 것
- 관계를 찾기 위해 중요한 feature들
- 아이템 자체나 유사 아이템과 사용자 간의 이전 상호작용을 반영하는 feature가 중요
- 예를들어, 비디오를 업로드한 채널에서 과거 유저가 해몇 개의 비디오를 봤는지 또는 마지막으로 언제 봤는지 등등이 중요
- candidate model이 비디오를 매긴 점수나 과거 비디오의 노출 빈도를 설명하는 feature
4.3 Embedding Categorical Features(카테고리 피쳐 전처리)
- 임베딩을 통해 sparse한 범주형 feature를 dense하게 만듦
- Unique ID Space(=vocabulary)비디오 id는 별도로 학습된 임베딩이 존재하고 이 중에 노출빈도를 기준으로 Top N개의 영상 및 검색이력을 임베딩함
- vocab에 없으면 zero embedding을 함
4.4 Normalizing Continuous Features
- 연속형 feature를 정규화 진행
- 누적분포(f)를 사용하여 [0,1) 사이의 값으로 스케일링
4.5 Modeling Expected Watch Time
- 사용자에게 주어진 영상의 시청시간의 기댓값을 예측하는 것이 목적
- Weighted Logistic Regression 사용하여 노출된 영상의 감상 시간을 가중치로 둠
- 예상 시청 시간

- T_i = i 번째 노출된 비디오의 시청시간
- N : 학습 데이터 수
- k : 노출된 영상 중 클릭한 예제 수
- 마지막으로 지수함수($e^x)$를 활성 함수로 사용하여 예상 시청 시간 $E(T)(1+P)$을 근접하게 추정하는 확률을 생성
5. Conclusion
- Cadidate generation과 ranking을 통해 기존 MF모델보다 높은 성능을 보임
- Example age와 같은 정보를 사용하여 과거에 치우치지 않고 새로운 비디오를 추천해주는 freshness(신선함) 반영
- ranking 모델에서 사용자의 과거 행동을 반영할 수 있는 feature를 추가하고 범주형이나 연속형 feature에 맞는 정규화방법을 사용하는 등 섬세한 feature engineer을 진행
- 시청시간에 대한 가중치를 사용하여 positive sample에 대한 시청시간 예측력을 높임
반응형